
SECTION 01
Ultrathinkとは何か|30秒でわかる機能と効果
Claude Codeには、AIの推論の深さを制御する仕組みが用意されています。通常の応答では表層的な判断で素早く返してくれますが、推論の深さを上げると内部の推論トークンが増え、より多くの角度から問題を検討してから回答を返します。
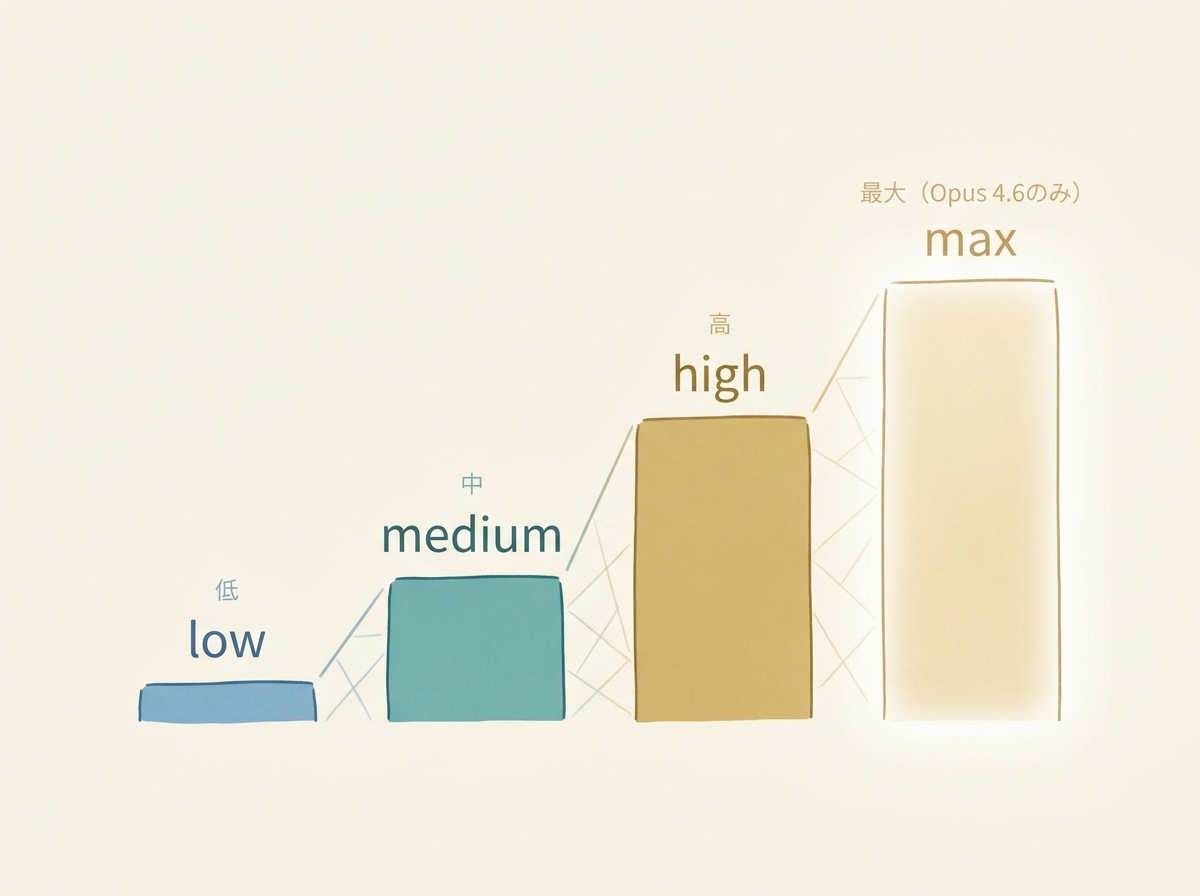
この推論の深さはeffort levelという仕組みで制御します。設定できるレベルは次のとおりです。
- low: 軽量な応答。単純な質問や定型作業向け
- medium: 標準的な推論。多くのタスクはこれで十分
- high: 深い推論。複雑なバグ特定やアーキテクチャ設計に向いている
- max: 最大限の推論深度。Opus 4.6のみ対応
effort levelの制御には、次の方法が使えます。
/effortコマンド: Claude Code内で/effort highのように指定する--effortフラグ: 起動時に--effort highを付けて実行するCLAUDE_CODE_EFFORT_LEVEL環境変数: 環境変数で既定値を設定する
ultrathink は、プロンプトに書くことでそのターンだけhigh effortを有効にするキーワードです。対応モデルでのみ機能し、一時的に推論を深めたいときに便利です。
注意点として、think や think hard は推論トークンを増やす正式なスイッチではありません。通常のプロンプト指示として処理されるだけで、effort levelを切り替える効果は保証されていません。確実に推論の深さを制御したい場合は、上記の公式な方法を使ってください。
深く考える分だけ、応答までの待ち時間とトークン消費は確実に増えます。常にオンにしておけばいいという機能ではなく、使いどころの見極めが実務では最も重要になります。
SECTION 02
Ultrathinkを使うべきタスク・使わないほうが速いタスク
高いeffort levelを使うかどうかの判断軸は、突き詰めると「一発で外したくない作業かどうか」です。やり直しのコストが高い作業には深い推論を使い、失敗してもすぐ直せる作業には通常のeffort levelで十分です。
精度が上がると実感できる場面は、次のようなタスクです。どれも共通して「間違った方向に進むと戻るのが大変」という特徴があります。
- 複数ファイルにまたがる複雑なバグの原因特定。再現手順と関連コードを渡して根本原因を推論させる
- アーキテクチャの設計判断。データフローや責務の分離をどう設計するか検討させる
- 大規模リファクタリングの計画。影響範囲が広く、手戻りが致命的になる変更の設計
一方、高いeffort levelを使う意味がほとんどない作業もあります。変数名の変更、定型的なCRUDコードの生成、単純なファイル操作などは通常モードのほうが圧倒的に速く、結果も変わりません。
この切り分けを意識するだけで、開発リズムを崩さずに精度を上げる場面だけ投資できるようになります。全部の作業にultrathinkを使うのは、全部の料理に高級オリーブオイルをかけるようなものです。
SECTION 03
著者の使い分けルール|速いモデルで試して、だめなら切り替える
自分がたどり着いた使い分けは非常にシンプルで、まず通常のeffort levelで試し、精度が足りなければ /effort high や ultrathink で上げるという流れです。最初から深い思考を使うのではなく、段階的に上げていくほうが結果的に速く正確にたどり着けます。
これはモデル選択にも同じことが言えます。常に最強の設定で動かすのは実は非効率で、応答が遅くなるぶん開発のテンポが崩れます。ちょっとしたコード修正に深い推論は要りません。
実際に2025年末ごろ、Opus 4.5のような高性能モデルを常時使っていた時期がありますが、コストがかなり高く、Maxプランでもすぐに使い切ってしまいました。深い推論を常時オンにするということは、それだけ消費が激しいということで、使いどころを絞らないと単純に予算が足りなくなります。
この経験から学んだのは、「常時オン」ではなく「必要なときだけオン」が唯一の正解だということです。逆に言えば、複雑なアーキテクチャ設計や計画を立てる場面には、待ち時間とコストを払う価値が確実にあります。
運用としては次のような流れに落ち着いています。
- まず通常のeffort levelで指示を出す。それで十分な品質なら完了
- 精度が足りない、あるいは考慮漏れがあると感じたら
/effort highやultrathinkに切り替える - 設計判断や複雑なバグ修正など、最初から精度が必要だと分かっている場面だけいきなり高いeffort levelを使う
SECTION 04
Ultrathinkの精度を最大化するコツ
ultrathinkを使うだけで自動的に精度が上がるわけではありません。深い思考の前に、指示の解像度を上げておくことが前提条件です。曖昧な指示に対してultrathinkをかけても、AIが迷う時間が増えるだけで出力の質は上がりません。
試行錯誤の中でたどり着いたのが、まず計画書を作らせてから実装に進むというプロセスです。要件を箇条書きで渡して、どのファイルをどう変更するか、どの関数を新規作成するかのステップバイステップの計画を先に出させます。この計画書のプロセスを挟むだけで、AIの理解度が格段に上がります。
具体的な併用順序は次のようになります。
- Plan Modeで計画を立てさせる。変更の全体像を整理する
- 計画をレビューして合意したら、
/effort highを設定して実装に進む - 実装中にズレを感じたら、一度止めて計画に戻る
ここで重要なのは、長考が始まったら意図ズレのサインかもしれないと疑うことです。AIに指示を出した後、異常に応答が遅かったり差分がプロジェクトの広範囲に及びすぎているときは、AIが指示の意図をわかっていないことが多いです。

以前は「もうちょっと待てば賢い答えが返ってくるかも」と粘って、関係ないファイルまで変更されて泥沼にはまることがありました。長考の原因が意図のズレにある場合は、早めにキャンセルしてプロンプトを見直すのが正解です。
SECTION 05
Claude Codeでの具体的な使い方・コマンド
effort levelの制御には、公式に用意された複数の方法があります。場面に応じて使い分けるのがポイントです。
セッション中に切り替える方法:
/effort high— そのセッション内のeffort levelをhighに設定します/effort max— Opus 4.6使用時のみ、最大の推論深度に設定します/model— 使用モデルを切り替えます。Opus 4.6(opus)に変更すればmax effortも使えます
起動時に指定する方法:
claude --effort high— 起動時にeffort levelを指定しますCLAUDE_CODE_EFFORT_LEVEL=high— 環境変数で既定値を設定します
プロンプト内で一時的に使う方法:
- 「ultrathinkで考えてからこのバグの原因を特定してください」— そのターンだけhigh effortが有効になります
- 「このアーキテクチャの問題点を洗い出してください」— ultrathinkキーワードなしの場合は、現在のeffort level設定に従います
CLAUDE.mdにeffort levelに関する指示を書くこともできますが、これはコンテキストとして読み込まれる指示であり、設定が自動適用されることを保証するものではありません。確実にeffort levelを制御したい場合は、/effort、--effort、CLAUDE_CODE_EFFORT_LEVEL を使ってください。
CLAUDE.mdに常時ultrathinkを指示するのも非推奨です。先述のとおり、全タスクに深い推論を適用するとコストと待ち時間が膨れ上がります。
もう一つ実務で使えるテクニックが、/clearでコンテキストをリセットしてからultrathinkを再投入する方法です。会話が長くなるとAIの注意が分散するので、バグ修正や設計でうまくいかないときは一度クリアして、必要な情報だけ渡し直すと精度が回復します。
SECTION 06
遅い・考えすぎる・答えが重いときの対処法
高いeffort levelを使い始めると、応答が異常に遅い場面に遭遇するのは避けられません。ただし「遅い=賢く考えている」とは限らないのが重要なポイントです。多くの場合、遅さはAIが指示の意図をつかめずに迷走しているサインです。
対処の基本は「粘らずにキャンセルする」ことです。長時間待った結果、関係ないファイルまで変更された差分が出てきた経験は一度や二度ではありません。待ち時間に比例して品質が上がるわけではないと割り切ることが大事です。
具体的な対処パターンを整理します。
- 応答が極端に遅い → プロンプトの指示が曖昧な可能性が高い。キャンセルして指示を具体化する
- 差分が広範囲に及びすぎる → タスクの粒度が大きすぎる。プロンプトを分割して段階的に進める
- 同じ箇所を何度も修正しようとする → コンテキストが汚れている。/clearでリセットする
Claude CodeにはRewind機能があり、重い処理を試して結果が悪ければ元に戻すという使い方がしやすくなっています。高いeffort levelで大きな変更を試みるときは、Rewindで戻せることを前提に実験的に使うのが精神的にも楽です。
最終的に大事なのは、ultrathinkを魔法の杖だと思わないことです。深い思考は道具であって、道具の効果は使う側の指示の質に依存します。遅いと感じたらまず自分のプロンプトを疑うのが、一番の近道です。
SECTION 07
他のモデル・ツールとの役割分担
ultrathinkだけで全ての開発作業をカバーしようとするのは現実的ではありません。高度な推論で設計し、実行は低コストなモデルに任せるという構造が、コストと品質のバランスでは最も合理的です。
この考え方はAIエージェントの設計にも通じます。最初にOpus 4.6のような高度な推論モデルで計画を立て、実行部隊をSonnet 4.6のような速いモデルで動かすというアーキテクチャです。ultrathinkの使い方もこれと本質的に同じで、重い思考は計画と判断の場面に集中させます。
現在の開発ツールは群雄割拠の状態で、毎週のようにツールの勢力図が変わります。どれか一つに全てを賭けるのはリスクが高く、場面ごとに使い分けるのが現実的です。
使い分けの考え方を整理すると次のようになります。
- 設計・計画・複雑な判断 → ultrathinkやOpus 4.6の高いeffort levelに投資する場面
- 定型的な実装・コード生成 → 通常のeffort levelやSonnet 4.6で十分な場面
- UI/デザイン系の作業 → ビジュアルに強いツールを選ぶ場面
重要なのは、特定のツールに依存しすぎない柔軟さを持つことです。今日のベストプラクティスが来月も通用するとは限りません。ultrathinkという機能自体も進化していくので、判断の「型」を身につけておくほうが、特定の設定を暗記するより長く使えます。
SECTION 08
実務での運用フロー|判断から実行までの流れ
ここまでの内容を踏まえて、日常の開発でeffort levelをどう使い分けるかの具体的なフローを整理します。ポイントは、毎回判断するのではなくパターン化してしまうことです。
ステップ1:タスクの性質を判断する。変数名の変更や定型コード生成なら通常のeffort level、複数ファイルにまたがる設計判断やバグ修正ならhigh effortの候補に入れます。判断に迷ったら、まず通常のeffort levelで試すのが原則です。
ステップ2:計画フェーズを挟む。高いeffort levelを使うと決めたら、いきなり実装指示を出さずにPlan Modeで計画を立てさせます。計画の質が実装の精度を決めるので、ここを飛ばさないことが重要です。
- 要件を箇条書きで明確に渡す
- 変更対象のファイルと関数を具体的に指定する
- 計画をレビューしてから実装に進む
ステップ3:実装と検証。計画に合意したら /effort high を設定して実装に進みます。応答が遅すぎる、差分が広がりすぎると感じたら躊躇なくキャンセルします。Rewind機能を使えば元に戻せるので、実験的に試す姿勢で臨みます。
SECTION 09
コストと待ち時間の判断基準
高いeffort levelを使うかどうかの判断で避けて通れないのが、コストと待ち時間のトレードオフです。深い推論はトークン消費が多く、応答時間も長くなります。これを「投資」と捉えるか「無駄」と捉えるかは、タスクの性質次第です。
投資として意味があるのは、やり直しのコストがeffort levelを上げるコストを上回る場面です。アーキテクチャの設計ミスを後から直す手間を考えれば、最初に深く考えさせるコストは安いものです。逆に、5秒で終わる修正に30秒待つのは明らかに割に合いません。
判断の目安を整理すると次のようになります。
- 高いeffort levelに投資すべき: 影響範囲が広い設計判断、再現が難しいバグ、本番に直結する変更
- 通常のeffort levelで十分: ローカルで完結する小さな修正、テストコードの追加、ドキュメント更新
もう一つ見落としがちなのが、開発リズムへの影響です。高いeffort levelの待ち時間は体感で通常モードの数倍になることがあり、テンポよく進めたい時間帯に挟むと集中力が途切れます。重い思考が必要なタスクは、まとめて処理するほうがリズムを守れます。
コスト管理の面では、プランの上限を意識しながら使う習慣が大切です。月の前半で高いeffort levelを使いすぎると後半に余裕がなくなります。重要な作業が控えている週は意識的に温存するなど、計画的な運用が求められます。



