SECTION 01
体感として最も速度差が出やすいのは実装フェーズ
「AIにすべて任せれば開発が速くなる」と期待してClaude Codeを使い始めると、思ったほど速くならない場面に必ずぶつかります。その原因はほとんどの場合、仕様があいまいなまま実装に入っていることにあります。
自分の経験から見えてきたのは、開発の工程を大きく3つに分けたときの体感的な配分です。最初の「何を作るか」を決める工程、真ん中の実装、最後の「動くけど何か違う」を直す工程という構成になります。
体感としては、最も速度差が出やすいのは真ん中の実装フェーズです。最初と最後は人間の判断が中心になりやすく、途中で「やっぱりこうしたい」が何度も発生すると、せっかくの速さが帳消しになります。
Anthropic公式の推奨フロー
ただし、Anthropic公式のBest Practicesでは、Claude Codeをコード生成だけでなく「explore(探索)→ plan(計画)→ implement(実装)」の一連のフローで活用することを推奨しています。
コードベースの調査や依存関係の把握、実装計画の策定、さらにはコミットやPR作成まで、Claude Codeの支援範囲として公式に案内されています。
つまり、最初に要件を固める時間を惜しまないことが全体のスピードを決めるのは変わりませんが、その「固める」プロセス自体にもClaude Codeを活用できるという点は押さえておくべきです。

SECTION 02
要件定義でClaude Codeに最初に渡す情報と順番
Claude Codeに要件を伝えるとき、情報を渡す順番が精度に直結します。いきなり画面の話から始めると、AIが全体像を見失ったまま細部を作り込んでしまいます。
自分のチームで安定しやすかったテンプレート
試行錯誤の中でたどり着いた渡し方の順番は、以下のとおりです。固定ルールではありませんが、自分の環境ではこの順序で渡すと出力が安定しやすいと感じています。
- ゴール:このプロダクトが解決したい課題を一文で
- 制約条件:使える技術スタック、期限、予算の上限
- ユーザー像:誰がどんな場面で使うか
- 画面遷移:主要な画面の流れ
- データ構造:扱う情報の種類と関連
ここで注意したいのは、渡しすぎても精度が落ちるという点です。一度に大量の情報を詰め込むと、AIが重要な箇所を見落としたり、矛盾した解釈をしたりすることがあります。
Anthropic公式が推奨するアプローチ
Anthropic公式のBest Practicesでは、上記のようなテンプレートの固定順ではなく、以下のアプローチが推奨されています。
- 具体的な文脈を十分に与える:プロジェクトの背景、技術スタック、制約を明確に伝えます
- Plan Modeを活用する:いきなり実装に入らず、まず計画を立てさせます
- Claudeに質問させる(AskUserQuestion):不足している情報をAI側から聞き返してもらいます
CLAUDE.mdに前提条件と禁止事項をあらかじめ書いておくのも有効です。「このプロジェクトではTypeScriptのみ使う」「特定のディレクトリ構成に従う」といったルールを設定ファイルに残しておけば、毎回の指示が減ります。
SECTION 03
誘導質問をやめて選択肢を出させるプロンプト設計
Claude Codeに「ここの処理はA→B→Cの順番で実装しますよね?」と聞くと、高確率で「そうですね」と返ってきます。AIはこちらの意見を忖度しがちで、仮に自分の案が最適でなくてもそのまま進めてしまいます。
これに気づいてからは、聞き方を根本から変えました。「この要件を満たすために最も効率的な処理フローの選択肢を3つ提案してください」という形にするだけで、自分が思いつかなかった手が出てきます。
誘導質問が危険なのは、自分が間違っているときに一番コストがかかるからです。AIが「はい、それでいいです」と返す裏で、実は非効率な設計が固まっていた、という事態を何度も経験しました。
要件の抜け漏れを減らすには、もうひとつ効果的な方法があります。AIに「この要件で足りない情報があれば質問してください」と明示的に指示するやり方です。
この逆質問プロンプトを使うと、自分では見落としていた観点を洗い出せます。具体的には以下のような指示が使えます。
- 「この仕様に矛盾している箇所があれば指摘してください」
- 「実装に入る前に確認すべき未定事項を列挙してください」
- 「このユーザーフローで想定漏れしている例外ケースを3つ挙げてください」
SECTION 04
実装前に必ず計画書を作らせる:プランモードの活用
複雑な機能を頼むとき、いきなりコードを書かせるのではなく「まず実装計画書を作って」と伝えるだけで仕上がりが変わります。この一手間が、後続のすべての作業の精度を決めるといっても過言ではありません。
具体的な流れは、自分が要件を箇条書きで渡す → AIが変更ファイル・関数・手順を含む計画を出す → 自分がレビューしてOKを出す → AIが実行するというステップです。この計画レビューを挟むことで、AIの理解度が格段に上がります。
計画書ステップを飛ばして一気にやらせると、大きな変更を一度に入れられて、どこで何が壊れたか分からなくなります。特に複数ファイルにまたがる変更では、この問題が顕著に出ます。
Plan Modeの使い分け
Claude CodeにはPlan Modeが用意されており、設計してから実装に入るワークフローを自然に組み込めます。Anthropic公式もPlan Modeの活用を推奨していますが、すべてのタスクで必須というわけではありません。
- 単一ファイルの軽微な修正 → Plan Modeを省略してそのまま実装してもOKです
- 複数ファイルにまたがる変更 → Plan Modeで設計してから入るのが安全側の運用です
- 新機能の追加 → 要件の箇条書き + 計画レビュー + 実装の3ステップが効果的です
計画の段階でファイル構成や依存関係のずれを発見できるので、手戻りが大幅に減ります。自分のチームでは、複数ファイル変更時はPlan Modeを必ず使うというルールにしています。
SECTION 05
機能要件と非機能要件を分けて詰める実践フロー
要件定義をClaude Codeに任せるとき、機能要件と非機能要件を分けて渡すだけで出力の質が変わります。一度にまとめて聞くと、パフォーマンスの話とUIの話が混ざって整理しにくくなります。
機能要件は画面単位で箇条書きにしてから渡すのが最も精度が高いです。「ログイン画面では何ができるか」「一覧画面のフィルタ条件は何か」という粒度で整理して、AIに仕様書フォーマットへ整形させます。
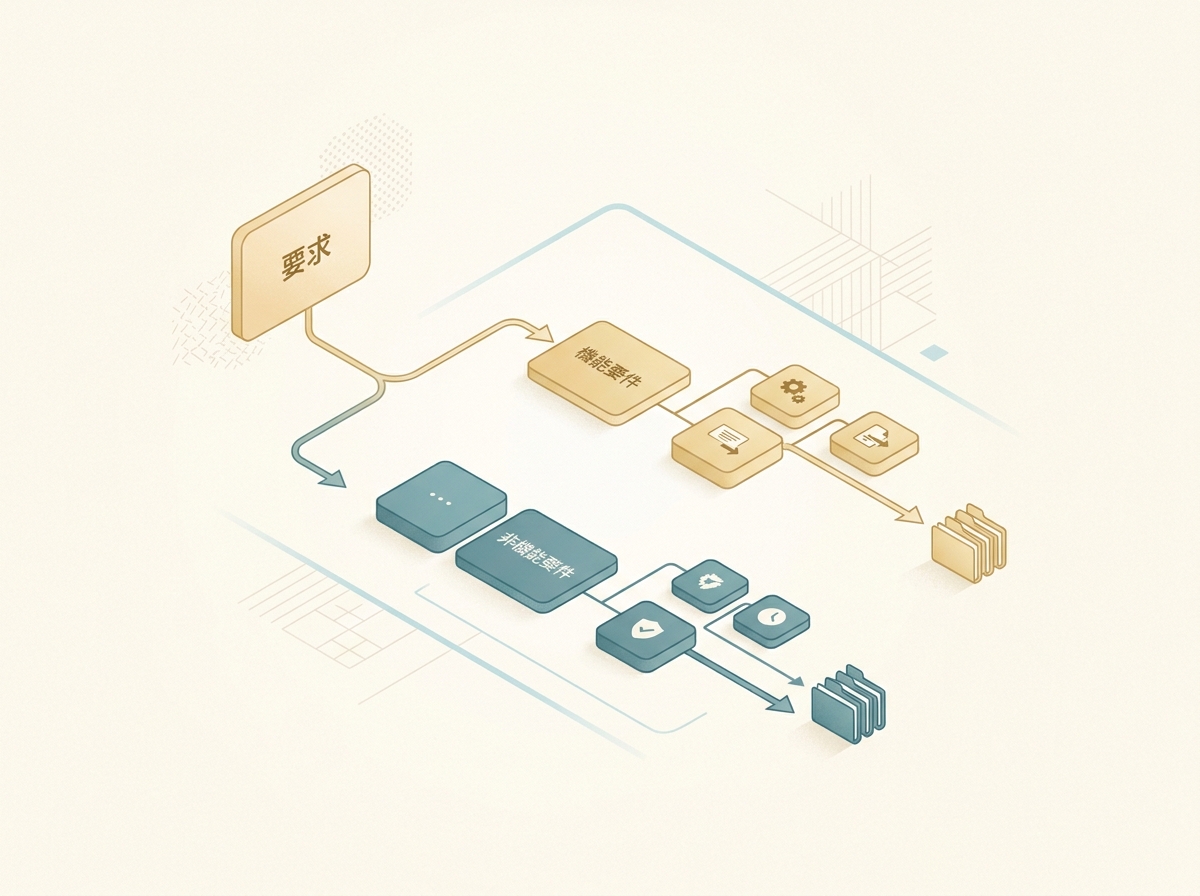
非機能要件は別のアプローチが有効です。パフォーマンス・セキュリティ・運用・保守といった観点をAIに列挙させてから、人間が取捨選択するという手順を踏みます。
ここで注意すべきなのは、AIが出す非機能要件は網羅的だが優先順位がないという点です。すべてを同じ重みで並べてくるので、「今回のリリースでは何が最優先か」を判断するのは人間の仕事になります。
- 機能要件:画面単位 → 箇条書き → AIに整形させる
- 非機能要件:AIに列挙させる → 人間が優先順位をつけて取捨選択
- 両方揃ったら → 計画書を作らせて全体の整合性を確認
SECTION 06
AIに任せていい判断と人間が握るべき境界線
Claude Codeとの協業で最も重要なのは、どこまでをAIに任せて、どこから人間が判断するかの線引きです。この境界があいまいなまま使い続けると、気づかないうちにAI任せの判断がビジネスに影響を与えます。
AIに安心して任せられる領域は明確です。仕様の整形、選択肢の列挙、要件の矛盾チェック、ドキュメントの生成はAIの得意分野であり、人間がやるより速くて漏れも少ないです。
一方、絶対に人間が握るべき判断もあります。ビジネス上の優先順位、ユーザー体験の最終判断、リリースの可否判断は、AIに委ねてはいけません。
- AIに任せてよい:仕様整形、選択肢列挙、矛盾チェック、ドキュメント生成
- 人間が握る:ビジネス優先順位、UXの最終判断、リリース可否
- 権限設計で制御する:コミット、外部接続、本番環境への操作
コミット権限は「渡さない」ではなく「設計する」
Anthropic公式では、コミットやPR作成はClaude Codeの正規ワークフローとして案内されています。permissionsの設定でgit commitを許可・確認・拒否のいずれかに設定できます。
つまり「コミット権限を一律に渡さない」のではなく、チームの監査要件やワークフローに応じてpermissionsを設計するのが正しいアプローチです。
- protected branchへのpushや本番操作は明示承認(ask)にする
- コミットは監査要件に応じて ask / deny / allow を設定する
- 安全側の運用として、自分のチームではコミット前に動作確認を挟むルールにしています
以前、コミットを自由に許可したところ、どんな粒度でコミットされるか、メッセージが何になるかをコントロールしにくくなりました。今は安全側の運用として「確認してからコミット」のフローにしていますが、これはチームポリシーであり、Claude Codeの制約ではありません。
SECTION 07
ハルシネーションで壊れた要件を検出するレビュー観点
AIが自信満々に出してくる仕様ほど、疑ってかかるべきです。存在しないAPIやライブラリを前提にした要件が紛れ込んでいることがあり、そのまま実装に入ると途中で破綻します。
ハルシネーションを検出するためのプロンプトとして有効なのは、「この要件に矛盾や実現不可能な前提がないかチェックして」という指示です。AIに自分の出力を再検証させることで、明らかな矛盾は事前に潰せます。
もうひとつ効果的な方法は、別セッションで同じ要件を再生成させて差分を見るやり方です。同じ入力から大きく異なる出力が出た場合、どちらかに根拠のない推測が混ざっている可能性が高いです。
- 出力に含まれる技術名・ライブラリ名が実在するかを必ず確認
- 要件間の依存関係に循環や矛盾がないかをチェック
- 「できます」と断言している箇所ほど根拠を問い直す
レビューの際は、AIの出力を鵜呑みにせず「本当にこの前提は正しいか」を一つずつ確認する習慣が必要です。面倒に感じますが、ここで手を抜くと後工程での手戻りが大きくなります。
SECTION 08
機密情報を伏せたまま要件相談するための入力ルール
要件定義では具体的なビジネス情報を扱いますが、機密情報の取り扱いはアカウント種別と設定によって条件が異なります。安全側の運用として、必要最小限の情報に置き換えてから渡すのが基本です。
アカウント種別ごとのデータ利用・保持条件
Claude Codeのデータの扱いはConsumerとCommercialで異なります。この違いを理解した上で、チームに合った運用を設計することが重要です。
- Consumer(無料・個人Pro):privacy settingsでデータの学習利用を管理できます。設定次第では入力が学習に利用される場合があります
- Commercial(Team・Enterprise):既定でデータは学習に使用されません。retention期間やZero Data Retention(ZDR)の設定も確認してください
- 全ユーザー共通:ローカルにtranscript cacheが既定で保存されます。ローカル保存設定も確認が必要です
安全側の運用として実践していること
実践的な対策としては、具体的な固有名詞をダミーに置き換えてから渡すのが最もシンプルです。「A社向けのECサイト」「予算はX万円」という形に置き換えても、要件定義の精度にはほぼ影響しません。
- 社名・顧客名・金額はダミーに置き換えてから入力
- API利用時のデータ取り扱いポリシーを事前に確認
- アカウント種別に応じたprivacy settings / retention設定を把握しておく
外部接続の制御はallowlistとsandboxで設計する
Anthropic公式では、外部接続を一律禁止するのではなく、CLI tools・MCP・WebFetchをpermissionsやallowlistの下で管理する運用が案内されています。
安全側の運用としては、デフォルトで広く許可せず、必要なCLI / MCP / ドメインだけをallowlistに追加するのが推奨されます。network request approvalやsandboxの併用も有効です。
- 外部接続は必要なものだけallowlistで許可する
- network request approvalを有効にして、意図しない通信を防ぐ
- sandboxを併用して実行環境を隔離する
何でも繋いで最大限に活用しようとするより、守備範囲を明確にしたほうが安心して深く使えます。要件定義のような上流工程では特に、情報の取り扱いに慎重であるべきです。
> 参考:Data usage、Security
SECTION 09
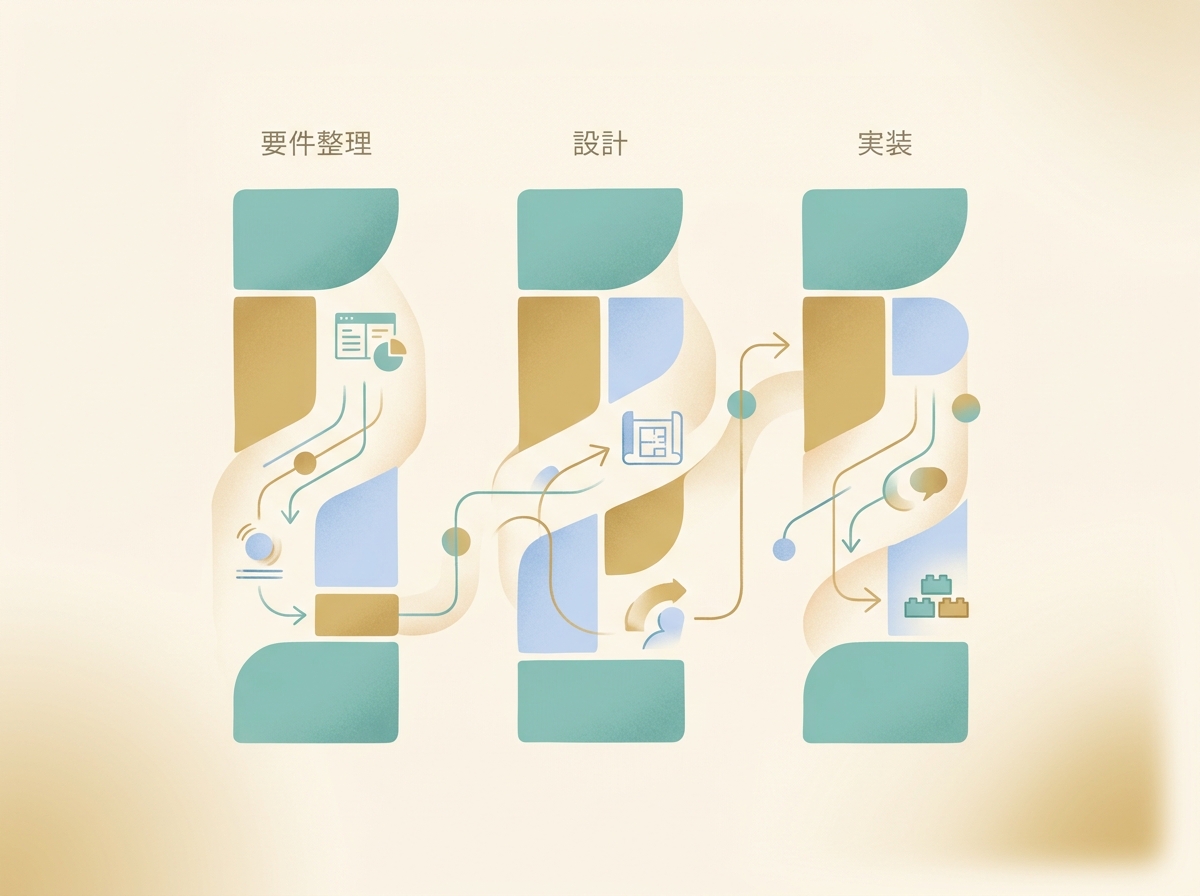
3つのセッション並列運用で要件定義から実装を高速に回す
要件が固まったら、複数のセッションを並列で走らせるのが現在の運用スタイルです。要件整理・設計・実装をそれぞれ別のセッションで進めることで、待ち時間がほぼゼロになります。
並列運用の前提:隔離された作業環境
Anthropic公式のBest Practicesでは、並列セッション自体を推奨しつつ、同一のワーキングツリーではなく隔離された環境を使うことが明記されています。
- git worktree:同一リポジトリから複数のワーキングツリーを切り出して使います
- Claude Code Desktopのisolated worktree:デスクトップ版では自動で隔離されたworktreeが作成されます
- Claude Code Web版のisolated VM:Web版ではセッションごとに隔離されたVMが提供されます
同一checkoutで複数セッションを走らせると、ファイルの競合や意図しない上書きが発生するリスクがあります。必ず隔離された環境を使ってください。
並列運用の実際の進め方
並列で走らせると、確認作業も並列で押し寄せてきます。すべてを細かく見るのではなく、結果のキュレーションと推奨アクションだけを見て判断するスタイルに切り替える必要があります。
この運用を続けていると、自分でコードを書く「プレイヤー」から、タスクを割り振って管理する「マネージャー」へ役割が変わった感覚があります。要件定義でしっかり方向を固めているからこそ、並列運用が破綻しません。
- セッション1:要件整理と仕様の言語化
- セッション2:設計と計画書のレビュー
- セッション3:実装と動作確認
並列運用の前提は、最初の要件定義が十分に固まっていることです。あいまいな状態で並列に走らせると、3つのセッションがそれぞれ別の解釈で進んでしまい、かえって混乱します。結局、すべては最初の要件定義に戻ってきます。



