SECTION 01
結論:利用経路で学習リスクはまったく違う
Claude Codeを業務に導入するとき、最初にぶつかる不安は「自分のコードが学習に使われるのか」という問いです。結論からいうと、この問いに対する答えは利用経路によってまったく異なります。
Anthropicの公式ポリシーでは、consumer向けのWeb利用(Free / Pro / Max) と商用利用(Team / Enterprise / API) で、データの取り扱いが大きく分かれます。
2025年8月28日以降、Free・Pro・Maxのいずれのプランでも、ユーザー自身が「model improvement」設定のオン/オフを選べる方式になっています。
ざっくりとした経路別の違いは以下のとおりです。
- Web(Free / Pro / Max): model improvement設定で学習利用の可否をユーザーが選択
- Team / Enterprise: 契約上のデータ保護あり、モデル学習に使われない
- API直接利用: 原則として学習に使われない(標準30日保持、zero data retentionも利用可能)
- AWS Bedrock / Google Cloud Vertex AI経由: Anthropicにデータが渡らない構造
重要なのは、「設定すれば大丈夫」で終わらせてはいけないということです。以前、法人向けのAIアシスタントサービスを運営していたとき、APIを使っているから学習に使われない、という点を明確に打ち出しました。企業で使う場合、顧客情報や社内ナレッジが会話に含まれる場面が避けられないからです。
オプトアウトのトグルを切り替えただけでは、データがどこを通っているかという根本的な問題は解決しません。どのプランで、どの経路を使い、データがどのサーバーに置かれるかという「経路の設計」として考える必要があります。
SECTION 02
Web利用(Free / Pro / Max)のデータの扱い
2025年8月28日以降、AnthropicはFree・Pro・Maxを同じconsumer usersとして扱い、データの学習利用についてはプランの違いではなく、ユーザー自身の「model improvement」設定で制御する方式に統一しています。
つまり、どのプランであっても、設定画面からmodel improvementをオフにすれば、通常のモデル改善目的での学習利用を止めることができます。
ただし、model improvementをオフにしても完全にデータが利用されないわけではありません。Anthropicの公式説明では、安全性審査でフラグされた会話などについては、安全対策の分析・向上のために使われうる例外があります。この点は認識しておく必要があります。
Team・Enterpriseプランでは、consumer向けとは別のポリシーが適用されます。具体的には以下のような違いがあります。
- Team: 組織単位でのデータ管理、モデル学習への利用が契約で制限される
- Enterprise: より厳格なデータ保持ポリシー、カスタム契約の交渉が可能
- いずれも: 管理者がメンバーの利用状況を一元管理できる仕組みが用意されている
ただし、Webインターフェースを使う限り、データはAnthropicのサーバーを経由するという点は変わりません。プランのグレードを上げることで契約上の保護は強まりますが、経路そのものが変わるわけではないことは理解しておく必要があります。
SECTION 03
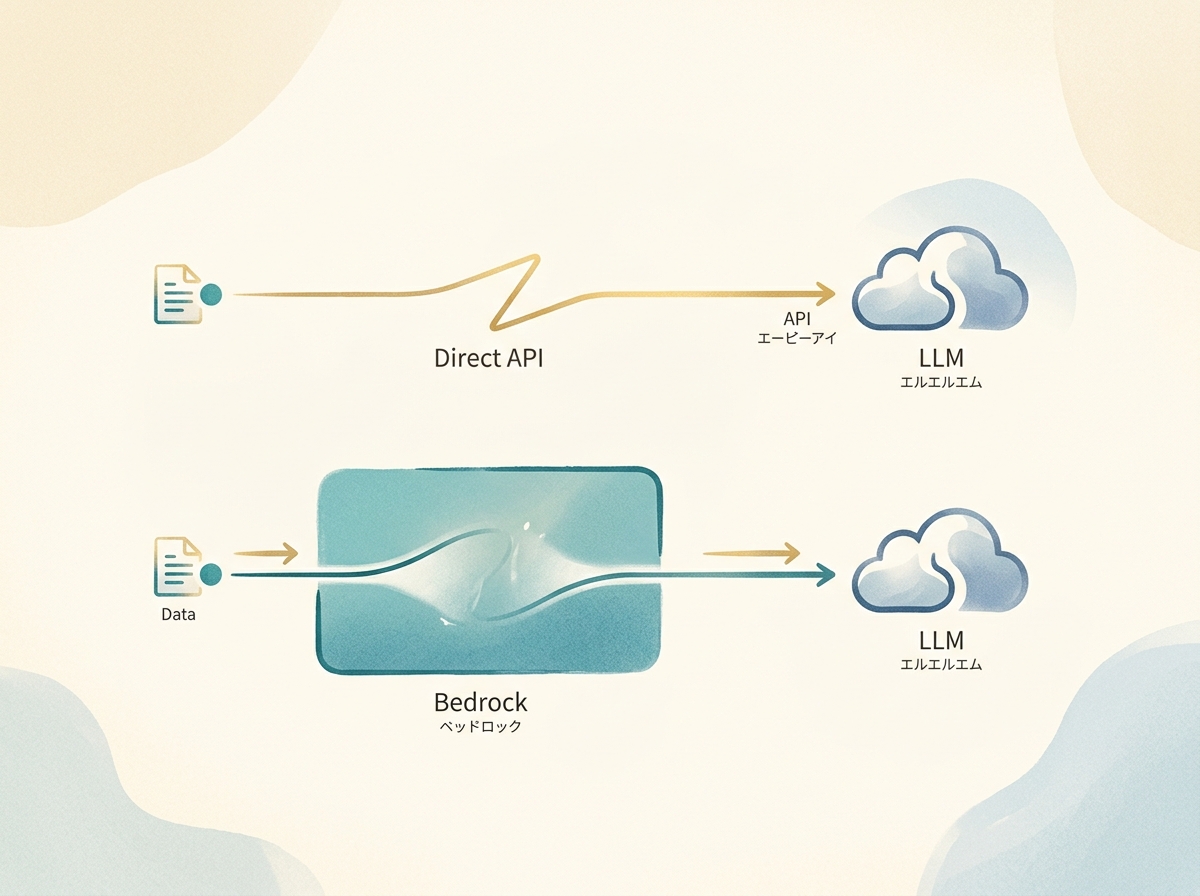
API経由のデータの扱い
AnthropicのAPIは、原則としてユーザーの入力をモデルの学習に使わないというポリシーを掲げています。これはOpenAIのAPIでも同様の方針が示されており、API課金型のサービスでは業界標準的な考え方です。
Claude CodeをAPI課金で使う場合、Anthropicの直接APIを叩く形になります。コードの送受信はAPI経由で行われるため、Web UIとは異なるデータ取り扱いルールが適用されます。
この「APIなら学習されない」という話は、ChatGPTが出てきた頃から自分も意識してきたことです。無料版のチャット画面にそのまま業務コードを貼り付けるのは危ない、というのはTwitterでも繰り返し書いてきました。APIか有料プランかという選択は、単なる機能の差ではなく、データをどこに渡しているかという問いでもあります。
ただしAPIであっても、以下の点は認識しておくべきです。
- データはAnthropicのサーバーに送られること自体は変わらない
- 商用ユーザー(Team / Enterprise / API)は標準で30日間のデータ保持が行われます
- 適切に構成したAPIキーではzero data retentionを利用することが可能です
- Anthropicの内部ポリシーが将来変更される可能性はゼロではない
つまり「APIだから完全に安全」ではなく、「学習に使われないという契約がある」という整理が正確です。データ保持期間やzero data retentionの設定まで含めて、企業利用では確認しておくべきポイントになります。
SECTION 04
AWS Bedrock経由で使うと何が変わるのか
AWS Bedrock(AWSが提供するマネージドAIサービス基盤)経由でClaudeを使う場合、データの流れそのものが根本的に変わります。ユーザーの入力はAWSのインフラ内で処理され、Anthropicにデータが渡らない構造になっています。
これは企業のセキュリティ要件にとって大きな意味を持ちます。VPC(仮想プライベートクラウド)内で通信を完結させたり、IAM(AWSの権限管理)でアクセス制御をかけたりと、既存のAWSセキュリティ基盤の上にClaude利用を載せることができます。
企業がBedrock経由を選ぶ主な理由は以下のとおりです。
- Anthropicにデータが送られない: 社内コードや顧客情報がSaaS事業者に渡ることへの懸念を解消できる
- 監査対応: CloudTrailなどAWSの監査ログと統合できる
- 既存のセキュリティポリシーとの整合: AWSを使っている企業なら追加の審査項目が少なくて済む
ただし、AnthropicのモデルがAWS/GCPの基盤上で動くことと、AWS/GCP側のログ・データ保持設定は別の問題です。Anthropicの学習対象にはなりませんが、AWS側のCloudWatch LogsやCloudTrailの設定、GCP側のCloud Loggingの設定については、利用企業側で別途確認・管理が必要です。
Claude CodeをBedrock経由で使う設定も技術的には可能です。環境変数でBedrock向けの接続先を指定することで、Claude Codeの操作感はそのままに、データの通り道だけをAWSインフラに切り替えることができます。
同じ「クラウド基盤経由」の選択肢として、Google Cloud Vertex AIもあります。こちらもGoogle Cloudのインフラ内でClaudeのモデルを利用できる仕組みで、GCPを主に使っている企業にとってはBedrockと同等の選択肢になります。
SECTION 05
オプトアウト設定の具体的な手順
Web版のClaudeを使っている場合、設定画面からmodel improvementのトグルを操作できます。以下のURLから直接アクセスできます。
claude.ai/settings/data-privacy-controls
手順としては以下の流れになります。
- claude.aiにログインし、設定(Settings)> Data Privacy Controlsを開く
- 「Model Improvement」に関するトグルを確認する
- モデル改善へのデータ利用をオフに切り替える
- 変更を保存して反映を確認する
なお前述のとおり、model improvementをオフにしても、安全性審査でフラグされた会話などは例外的に分析対象となりうる点は覚えておいてください。
オプトアウトしたからといって経路の問題は解決しないという点は繰り返し強調しておきます。生成AIの導入について書いた記事でも触れたことですが、「まあAIだから大丈夫でしょ」で設定を確認しないまま使い続けている人が企業の中にかなりいる印象があります。オプトアウトは最低限の手続きであって、本質はどの経路でデータを流しているかの設計です。
SECTION 06
著者がMax Planを選んだ理由:料金とClaude Code活用の両面
Claude CodeにはAnthropic APIの従量課金で使う方法と、Pro / Maxなどのサブスクリプションで使う方法があります。自分は迷わずMax Planを選びました。
理由は二つあります。一つはコスト面で、朝から晩まで開発していると、API課金では請求がかなりの金額になります。料金を気にしながら使うと、変に萎縮して開発が止まるという実体験がありました。
もう一つは利用制限の余裕です。Maxはconsumer向けプランの中で最も利用枠が大きく、開発に集中しやすい環境を得られます。
なお、データの学習ポリシーについては、MaxもFree・Proと同じconsumer向けの設定が適用されます。プランの違いで学習対象から外れるわけではなく、model improvement設定のオン/オフで制御する仕組みは全プラン共通です。安全性の差はプランそのものではなく、ユーザー自身のprivacy設定の選択によります。
実際にMax Planで制限にかかったことはほとんどなく、料金を気にせず集中できるのが最大のメリットでした。コストの予測可能性と十分な利用枠、この二つを同時に得られる選択肢として、個人開発者には合理的な選択だと感じています。
もちろん、チームでの利用や顧客情報を扱う場面では、Max Planだけでは不十分なケースもあります。その場合はTeam / Enterprise、あるいはBedrock経由を検討する段階に入ります。
SECTION 07
個人開発と法人利用で安全な経路はどう変わるか
個人開発で自分のコードだけを扱う場合、許容できるリスクの範囲は比較的広くなります。API直接利用やPro / Maxプランであれば、model improvement設定をオフにした上で開発を進めることができます。
一方、チームで使う場合や顧客情報が絡む場合は、経路設計そのものから見直す必要があります。「誰が何をAIに入力したか」を管理できる仕組みがないと、一人のミスで情報が流れるリスクがあるからです。
法人利用で確認すべき項目は以下のとおりです。
- 利用経路: Web UI / API / Bedrock / Vertex AIのどれを許可するか
- アクセス権限: 誰がClaude Codeを使えるか、どのリポジトリで使えるか
- 入力制限: 顧客データ・認証情報・社内機密をAIに渡さないルールの有無
- 監査ログ: 誰がいつ何を入力したかを追跡できるか
- データ保持: API利用時の保持期間設定(標準30日 / zero data retention)を確認済みか
- プライバシー設定: 組織全体でmodel improvement設定がオフになっているか確認済みか
情シスや開発リーダーが導入判断をする場面では、「便利だから入れよう」の前に、データの通り道を図に描くくらいの手間をかけたほうがよいです。後から「実は学習に使われていた」となったときのダメージは、設定一つで済む話では収まりません。
これまでの経験として、セキュリティの穴は後から塞ぐのが一番コストが高いと何度も実感してきました。AIツールも例外ではなく、導入の初期段階で経路とルールを決めておくことが、結果的に一番安く済みます。
SECTION 08
Claude Codeで「任せる範囲」をどう決めているか
Claude Codeを使い始めた最初に、安全のためにいくつかの制限を自分で設定しました。勝手にコミットしない、データベースを破壊する操作は禁止、Docker関連にも制限をかけています。
コードを書く速度が上がると、逆に「どこまで任せてよいか」の境界線を明確にしないと怖くなってきます。AIが速く動けるからこそ、暴走したときの被害も速く広がるからです。
自分が線引きしているポイントは以下です。
- コミット: 自動コミットは禁止。必ず自分で差分を確認してからコミットする
- DB操作: 破壊的なマイグレーションやデータ削除は禁止
- 外部接続: MCPは使わない。予期しない外部サービスへの接続を防ぐため
- 認証情報: 環境変数やAPIキーをAIに渡さない運用ルール
MCPを使わない判断は、セキュリティの考え方として「情報をなるべく持たない」「なるべく外に出さない」という原則の延長にあります。便利な拡張機能であることは理解していますが、勝手にいろんなところに接続されて予期しない操作が起きるリスクを、現時点では許容できないと判断しています。
多くのサービスを開発してきた経験からいえるのは、セキュリティは「やりすぎ」くらいでちょうどいいということです。AIに任せる範囲を広げるほど、自分でコントロールできる範囲を意識的に設計しておく必要があります。
SECTION 09
導入前に確認すべきチェックリスト
ここまでの内容を踏まえて、Claude Codeを安全に導入するための確認項目を整理します。個人開発者でもチーム導入でも、最低限これだけは確認しておくべきポイントです。
個人開発者向けの確認項目はこちらです。
- model improvement設定を
claude.ai/settings/data-privacy-controlsで確認・オフにしたか - 安全性審査でフラグされた会話などの例外が存在することを理解しているか
- Claude Codeの初期設定で危険な操作を制限したか
- 認証情報やAPIキーをAIの入力に含めない運用ルールを決めたか
チーム・法人導入の場合は、さらに以下が加わります。
- 利用経路(API / Bedrock / Vertex AI)を組織として決定したか
- API利用時のデータ保持設定(標準30日保持 / zero data retention)を確認したか
- データがどのサーバーを経由するかを図に描いて確認したか
- Bedrock / Vertex AI利用時にAWS / GCP側のログ・保持設定も確認したか
- 監査ログの取得方法を確保しているか
- メンバーの利用範囲と入力ルールを文書化したか
- セキュリティ部門や法務の承認プロセスを通したか
これらの項目は、一度確認して終わりではなく、定期的に見直すことが大切です。AIサービスのポリシーはアップデートのたびに変わる可能性があり、半年前に確認した内容がそのまま有効とは限りません。
「面倒だから後で」と先送りにすると、気づかないうちにリスクを抱えたまま運用が広がっていくのがAIツールの怖いところです。導入初期に決めたルールを、チーム全員が認識している状態を維持することが、実務的には一番重要なセキュリティ対策になります。
SECTION 10
まとめ:経路を選ぶことがセキュリティの第一歩
Claude Codeの学習リスクは、どの経路で使うかによって根本的に変わります。consumer向けのWeb利用(Free / Pro / Max)ではmodel improvement設定で学習利用の可否を選択でき、APIでは原則として学習されず(標準30日保持)、Bedrock経由ならAnthropicにデータが渡らない構造になります。
「オプトアウトしたから安心」ではなく、データがどこを通っているかという経路の問題として捉え直すことが、実務では一番大切です。設定の有無だけでなく、プランの選択、経路の設計、運用ルールの策定まで含めて考えるべきテーマです。
試行錯誤の中で辿り着いたのは、AIに任せる範囲を広げるほど、自分でコントロールする範囲も広げなければならないという原則です。速さと安全のバランスは、事前の設計で決まります。
この記事が、Claude Codeの導入を検討している方の判断材料になれば幸いです。技術は変わっても、「情報をなるべく外に出さない」というセキュリティの基本は変わりません。